たくさんの4x4行列の積
GPUは多量のデータを処理するのに向いているらしいので、よくある行列の積を計算するやつを作ってみた。
ただし大きな行列が速く計算できるというのは割とよく見るので、3次元画像処理でよく出てくる4x4行列の積をたくさん(100万個×10回)計算してみた。
matrix_mult.cu:
__global__ void mult_matrix(float* C, const float* A, const float* B) { const size_t d(threadIdx.z); const size_t offset(16*(blockIdx.x*DIV + d)); const size_t index(threadIdx.x + blockDim.y*threadIdx.y); __shared__ float _A[DIV][4*4], _B[DIV][4*4]; _A[d][index] = A[offset + index]; _B[d][index] = B[offset + index]; float c_elem = 0.0; for (int k = 0; k < 4; ++k) { c_elem += _A[d][threadIdx.x + 4*k] * _B[d][k + 4*threadIdx.y]; } C[offset + index] = c_elem; }
カーネルはあまり考えてない。各スレッドが答えの行列の1要素をそれぞれ計算する。 もう少し並列計算っぽい雰囲気を出したい気もするけど、掛けて足す(積和演算)を1命令(fma)で処理できるらしいので、それに期待してみた。
うちのボード(GeForce GTX 670)だと理論値は約2460 [GFLOPS]らしい。どきどき。
実行結果
1 CPU: 546.0 [ms] (2.2 GFLOPS) kernel: 1.69661 [ms] (69.2208 GFLOPS) kernel: 1.6952 [ms] (69.2783 GFLOPS) kernel: 1.69296 [ms] (69.3699 GFLOPS) kernel: 1.69197 [ms] (69.4106 GFLOPS) kernel: 1.69302 [ms] (69.3673 GFLOPS) kernel: 1.69402 [ms] (69.3267 GFLOPS) kernel: 1.692 [ms] (69.4093 GFLOPS) kernel: 1.69446 [ms] (69.3084 GFLOPS) kernel: 1.6921 [ms] (69.4053 GFLOPS) kernel: 1.69213 [ms] (69.404 GFLOPS) GPU: 328.0 [ms] (3.6 GFLOPS)
CPU(Core i7 3770)の方はVisual C++ 2010 expressが自動並列化とかしてくれないらしくSIMD命令を使ってない上、OpenMPもライブラリが無くて使えなかったので参考程度。本気を出せば、この32倍くらいは出るかも。
で、GPUの方だけど。・・・えー、100万個の行列積は1.7 [ms]弱で計算できてるけど、それ以外の所に18倍くらいの時間がかかってる。。 っていうか、カーネルだけの演算性能も理論値の2.8%強しか出てない。
原因はおそらく、コレ。
> bandwidthTest.exe --memory=pinned <pre> [bandwidthTest.exe] starting... bandwidthTest.exe Starting... Running on... Device 0: GeForce GTX 670 Quick Mode Host to Device Bandwidth, 1 Device(s), Pinned memory Transfer Size (Bytes) Bandwidth(MB/s) 33554432 11822.3 Device to Host Bandwidth, 1 Device(s), Pinned memory Transfer Size (Bytes) Bandwidth(MB/s) 33554432 12040.7 Device to Device Bandwidth, 1 Device(s) Transfer Size (Bytes) Bandwidth(MB/s) 33554432 150019.5 [bandwidthTest.exe] test results... PASSED
Host <-> Device間はとりあえずおいといて、Device間の方をみると大体150 [GB/s]の転送速度らしい。4x4行列の積を1回計算するには2個の行列を読み込んで1個の行列を書き込む必要があるので、各要素が単精度実数とすると192 [byte]のデータ転送が発生する。つまり、毎秒約7800万組のデータが転送できる計算になる。4x4行列の積の計算量(和と積の数)は112なので、この転送速度だと毎秒87.5Gの浮動小数点演算が発生する。あ、上で見た数字70Gに近いね。ひょっとしたらメモリの読み書きが同時にできるかもしれないけど、まあ、それはそれ。
単純計算だと、
![\frac{150 \ \text{GB}}{3 n^2 \cdot 4 \ \text{B}} \cdot n^2 (2n - 1) = 12.5 \cdot (2n - 1) \geq 2460 \ [\text{GFLOPS}]](/wiki/images/math/0/6/c/06ce83a4512159039d02b4c63d7bec5e.png)
となる最小の整数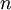 は99なので、少なくともうちの環境では行列の大きさがもっと大きくならないと計算量に対してデータの転送量が追いつかないということになる。従って、GPUはそのほとんどの時間を手持ちぶさたで過ごしていたようだ。
は99なので、少なくともうちの環境では行列の大きさがもっと大きくならないと計算量に対してデータの転送量が追いつかないということになる。従って、GPUはそのほとんどの時間を手持ちぶさたで過ごしていたようだ。
さらに言えばHost <-> Device間はもう一桁遅いので、大量の小さな行列を毎回Device側に転送して計算するような処理は効率が悪くなる。ただし、Host側とのデータ転送が無い場合は小さな(多量の)問題をGPUで処理してもCPUで解くのと遜色ない性能が出るとも考えられる。
というわけで、入力に対して途中計算が爆発的に増える組み合わせ計算のような処理向きかな、と思った。